تعارفی ڈیپ لرننگ پریکٹیکل کامبیٹ (1): الگوریتھک وان گوگ طرز کی تصویر تیار کرتا ہے جیسے پریزما
تعارف: مصنوعی ذہانت اب ایک پُرجوش موضوع ہے ، اور مصنوعی ذہانت مشین سیکھنے سے لازم و ملزوم ہے ۔مشین سیکھنے میں گہری تعلیم حاصل کرنا ایک زیادہ مقبول سمت ہے۔ مضامین کا یہ سلسلہ اصل لڑائی سے شروع ہوگا اور گہری سیکھنے کے لئے ایم ایکس نیٹ کو استعمال کرنے کا طریقہ متعارف کرائے گا ~ چونکہ یہ اصل لڑائی ہے اور یہ مضمون اندراج کی سطح ہے ، ہم اتنے ریاضیاتی فارمولوں کے بارے میں بات نہیں کریں گے جن کو ہر کوئی سمجھ نہیں سکتا ~
دیپ لرننگ کا تعارف 0x00
اگرچہ ، ہم گہری ریاضیاتی اصولوں کے بارے میں بات نہیں کرتے ہیں ، لیکن بنیادی اصولوں پر عبور حاصل ہونا چاہئے
گہری سیکھنے کو متعارف کرانے سے پہلے ، ہمیں پہلے دو تصورات ، مشین لرننگ اور عصبی نیٹ ورک کو سمجھنا چاہئے۔
مشین لرننگ:
گہری سیکھنے کو متعارف کروانے سے پہلے آئیے مختصر طور پر مشین لرننگ کو متعارف کرائیں۔ آئیے وکی پیڈیا پر مشین لرننگ کی تعریف کا حوالہ دیتے ہیں۔
مشین لرننگ مصنوعی ذہانت کی ایک شاخ ہے۔ مصنوعی ذہانت کی تحقیق "استدلال" پر توجہ مرکوز کرنے سے "علم" پر "سیکھنے" پر توجہ دینے تک ایک فطری اور واضح تناظر ہے۔ ظاہر ہے ، مشین لرننگ مصنوعی ذہانت کا ادراک کرنے کا ایک طریقہ ہے ، یعنی مشین لرننگ کے ذریعے مصنوعی ذہانت میں موجود مسائل کو حل کرنا۔ پچھلے 30 سالوں میں ، مشین سیکھنے نے ایک کثیر فیلڈ بین الضابطہ مضمون میں ترقی کی ہے ، جس میں امکانی تھیوری ، اعدادوشمار ، تخمینی نظریہ ، محدب تجزیہ ، کمپیوٹیشنل پیچیدگی کا نظریہ اور دیگر مضامین شامل ہیں۔
مشین لرننگ تھیوری بنیادی طور پر کچھ الگورتھم ڈیزائن اور تجزیہ کرنا ہے جو کمپیوٹروں کو خود بخود "سیکھنے" کی اجازت دیتے ہیں۔ مشین لرننگ الگورتھم ایک طرح کا الگورتھم ہے جو خود بخود تجزیہ کرتا ہے اور ڈیٹا سے قواعد حاصل کرتا ہے ، اور نامعلوم اعداد و شمار کی پیش گوئی کرنے کے لئے قواعد کو استعمال کرتا ہے۔ چونکہ الگورتھم سیکھنے میں شماریاتی نظریات کی ایک بڑی تعداد شامل ہے ، لہذا مشین لرننگ خاص طور پر مابعد کے اعدادوشمار سے بہت قریب سے تعلق رکھتی ہے ، جسے شماریاتی نظریہ بھی کہا جاتا ہے۔ الگورتھم ڈیزائن کے ضمن میں ، مشین لرننگ تھیوری حصول اور موثر سیکھنے الگورتھم پر مرکوز ہے۔ بہت سے تخمینے والے مسائل پر عمل کرنا مشکل ہے ، لہذا مشین لرننگ ریسرچ کا ایک حصہ تخمینی الگورتھم تیار کرنا ہے جس کو سنبھالنا آسان ہے۔
سیدھے الفاظ میں ، مشین لرننگ یہ ہے کہ مشین کو قواعد ڈھونڈنے کے ل the اعداد و شمار کا تجزیہ کرنے دیں ، اور پائے گئے قواعد کے ذریعے نئے ڈیٹا پر کارروائی کی جائے۔
عصبی نیٹ ورک:
نیوران:
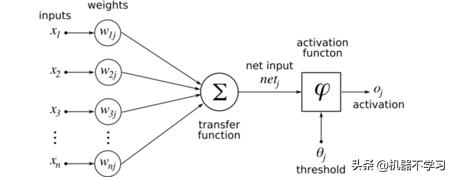
مثال کے طور پر ایک تصویر لینا ، ہر ڈیٹا یا ان پٹ ایک تصویر ہے ، اور اس میں ہر ایکس تصویر میں ہر ایک پکسل ہوسکتا ہے۔ ہر ایک پکسل کے ل we ، ہم ایک وزن تفویض کرتے ہیں ، اور پھر ایک ویلیو حاصل کرنے کے لئے ٹرانسفر فنکشن (ٹرانسفر فنکشن ، یہاں ایک لکیری سپرپوزیشن ہے) سے گزرتے ہیں۔ سیدھے الفاظ میں ، ہم تمام پکسلز کی ایک لکیری وزنیٹ سپرپوزیشن کرتے ہیں۔ حاصل کی گئی قیمت ایک نئی قیمت حاصل کرنے کے ل the ایکٹیویشن فنکشن سے گزرے گی۔ یہ ایکٹیویشن فنکشن اکثر ایک غیر لکیری فنکشن ہوتا ہے جو کچھ خصوصیات کو پورا کرتا ہے۔ ہمیں غیر لکیری تبدیلی کی ضرورت کیوں ہے؟ ایک سادہ سی مثال دینے کے لئے ، اسی طیارے میں آپ اور آپ کا سایہ اوورپلاپ ہوجاتا ہے اور اسے الگ نہیں کیا جاسکتا ، لیکن ایک جہتی جگہ میں آپ کو الگ کیا جاسکتا ہے۔ غیر خطوطی تبدیلی کا بھی ایسا ہی اثر ہے۔ عام طور پر استعمال شدہ ایکٹیویشن کے افعال ریلو ، سافٹ میکس ، ٹنہ ہیں۔
سیدھے الفاظ میں ، نیورون ایک سادہ درجہ بند ہے ، آپ درج کریں
مثال کے طور پر ، ہمارے پاس بلیوں اور کتوں کی بہت ساری تصاویر ہیں اور ہر تصویر کسی مشین کو بھیجی جاتی ہے ، اور مشین کو یہ طے کرنے کی ضرورت ہے کہ اس تصویر میں موجود چیز بلی یا کتے کی ہے۔ آئیے بلی اور کتے کی تصاویر پر کارروائی کریں ، بائیں طرف کتے کا فیچر ویکٹر ہے ، اور دائیں طرف بلی کی طرف ہے
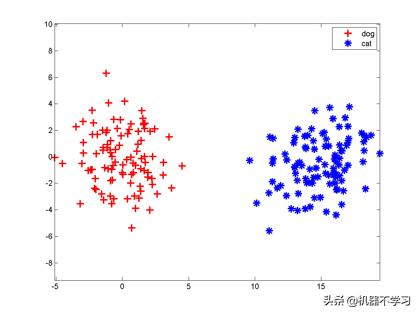
اس کے بارے میں سوچئے ، ان دو سیٹوں کو نمایاں کرنے والے ویکٹر کو الگ کرنے کا آسان ترین طریقہ کیا ہے؟ بالکل ، اعداد و شمار کے دونوں سیٹوں کے درمیان ایک عمودی لکیر کھینچیں ، جس میں بائیں طرف کتا اور دائیں طرف بلی ہے ، اور درجہ بندی مکمل ہے۔ بعد میں نئے ویکٹر کے ساتھ ، لائن کے بائیں طرف گرنے والے سبھی کتے ہیں ، اور دائیں طرف پڑنے والے بلیوں ہیں۔
ایک سیدھی لائن طیارے کو دو حصوں میں تقسیم کرتی ہے ، ہوائی جہاز تین جہتی خلا کو دو حصوں میں تقسیم کرتا ہے ، اور ایک N-1 جہتی ہائپرپلیٹ این جہتی خلا کو دو حصوں میں تقسیم کرتا ہے ۔دونوں اطراف دو مختلف اقسام سے تعلق رکھتے ہیں۔اس درجہ بندی کو اعصابی کہا جاتا ہے۔ یوآن
یقینا ، مذکورہ تصویر میں ، ہم نے صرف یہ سیکھا کہ "عمودی لکیر دو قسموں کو" خدا کے نقطہ نظر سے الگ کر سکتی ہے۔ جب ہم واقعی نیورانوں کی تربیت کرتے ہیں تو ، ہمیں نہیں معلوم کہ خصوصیات کو ایک ساتھ کس طرح جوڑا گیا ہے۔ نیورون ماڈل کے سیکھنے کے ایک طریقہ کو ہیب الگورتھم کہا جاتا ہے:
پہلے تصادفی طور پر سیدھی لکیر / ہوائی جہاز / ہائپرپلیون کا انتخاب کریں ، اور پھر نمونے ایک ایک کرکے لیں۔اگر لائن کو غلط طریقے سے تقسیم کیا گیا ہے تو اس کا مطلب یہ ہے کہ نقطہ غلط سمت پر تقسیم ہوا ہے ۔اس نمونے کے قریب سیدھی لائن کو تھوڑا سا قریب منتقل کریں اور اسے عبور کرنے کی کوشش کریں۔ اس نمونے کو پاس کریں اور اسے سیدھے لائن کے دائیں طرف چلائیں let اگر سیدھی لائن ٹھیک ہے تو ، یہ عارضی طور پر رک جائے گی۔ لہذا ، نیورانوں کی تربیت کا عمل یہ ہے کہ یہ سیدھی لکیر مستقل طور پر ناچ رہی ہے ، اور آخر کار دو طبقوں کے درمیان عمودی لائن پر چھلانگ لگاتی ہے۔
عصبی نیٹ ورک:
عصبی نیٹ ورک کا آسان سا نقطہ بہت سے نیورانوں پر مشتمل نظام ہوگا۔
نیورون کا ایک نقصان یہ ہے کہ یہ صرف چھری کاٹا سکتا ہے! مجھے بتائیں کہ آپ کس طرح ایک چھری سے درج ذیل دو اقسام کو الگ کرسکتے ہیں۔
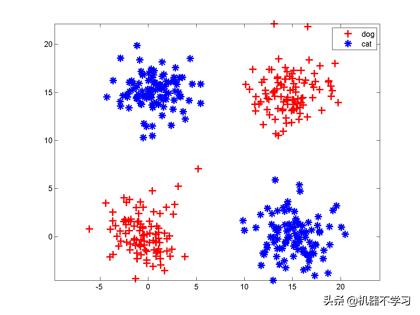
حل ایک ملٹی لیئر عصبی نیٹ ورک ہے ، اور نچلے درجے کے نیورون کا آؤٹ پٹ اعلی سطحی نیورون کا ان پٹ ہے۔ ہم وسط میں افقی طور پر کاٹ سکتے ہیں اور عمودی طور پر کاٹ سکتے ہیں ، اور پھر اوپر بائیں اور نیچے دائیں حصوں کو ایک ساتھ جوڑ سکتے ہیں اور اوپری دائیں اور نچلے بائیں حصوں کو الگ کرتے ہیں or یا اس حصے کو کھودنے کے لئے اوپری بائیں کونے کے ارد گرد 10 چاقو کاٹ سکتے ہیں ، اور پھر نیچے دائیں کونے میں ضم کریں۔
جب بھی کٹ تیار ہوجاتا ہے ، ایک نیورون درحقیقت مختلف کٹ آدھے طیاروں پر چوراہا اور یونین آپریشن انجام دینے کے لئے استعمال ہوتا ہے ، جس کا مطلب یہ ہے کہ ان نیورانوں کے آؤٹ پٹ کو ان پٹ کے بطور استعمال کیا جا. ، اور پھر ایک اور نیورون کو جوڑا جائے۔ اس مثال میں ، خصوصیت کی شکل کو XOR کہا جاتا ہے۔ اس معاملے میں ، ایک نیوران اسے سنبھال نہیں سکتا ، لیکن نیوران کی دو پرتیں اس کی صحیح درجہ بندی کرسکتی ہیں۔
جب تک آپ کافی چاقو کاٹ کر نتائج کو ایک ساتھ رکھ سکتے ہیں ، کوئی بھی عجیب و غریب حد کا نیورل نیٹ ورک نمائندگی کرسکتا ہے ، لہذا عصبی نیٹ ورک نظریاتی طور پر انتہائی پیچیدہ افعال / مقامی تقسیم کی نمائندگی کرسکتا ہے۔ تاہم ، چاہے اصلی عصبی نیٹ ورک صحیح پوزیشن میں تبدیل ہوسکتا ہے اس کا انحصار ابتدائی نیٹ ورک ویلیو سیٹنگ ، نمونہ کے سائز اور تقسیم پر ہوتا ہے۔
گہری سیکھنے:
تو کیا گہری سیکھنے ہے؟ سیدھے الفاظ میں ، گہری لرننگ ایک نئی ڈھانچے اور نئے طریقوں کا ایک سلسلہ ہے جو ایک ایسی کثیر پرت کے اعصابی نیٹ ورک کی بڑی تعداد میں تربیت اور چلانے کی اجازت دینے کے لئے تیار ہوا ہے۔
ذیل کی تصویر کو پسند کریں
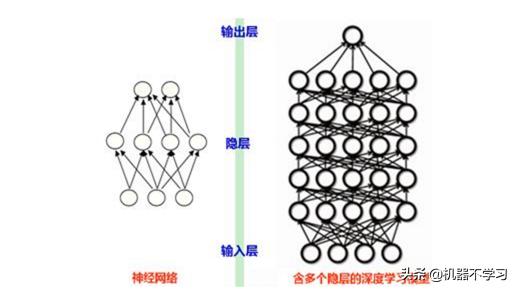
ایک عام اعصابی نیٹ ورک میں صرف کچھ پرتیں ہوسکتی ہیں ، اور گہری سیکھنے سے ایک درجن سے زیادہ تہوں تک پہنچ سکتی ہے۔ گہری سیکھنے میں لفظ کی گہرائی عصبی نیٹ ورک کی پرتوں کی تعداد کی بھی نمائندگی کرتی ہے۔ مقبول گہری سیکھنے والے نیٹ ورک ڈھانچے میں "سی این این (کنونیوژن نیورل نیٹ ورک) ، آر این این (سرکلر نیورل نیٹ ورک) ، ڈی این این (ڈیپ نیورل نیٹ ورک) ، وغیرہ شامل ہیں۔
یقینا، ، ہم اصل لڑاکا پر مبنی ہیں اور مارکیٹ میں موجودہ کچھ گہری سیکھنے والے فریم ورک کو براہ راست استعمال کرسکتے ہیں۔ مقبول گہری سیکھنے والے فریم ورکز ایم ایکس نیٹ ، ٹینسر فلو ، کیفے ، وغیرہ ہیں۔ یہ مضمون بنیادی طور پر ایم ایکس نیٹ کو متعارف کراتا ہے ، جو ایک عمدہ اوپن سورس گہری سیکھنے کا فریم ورک ہے۔
0x01 MXnet انسٹال کریں
یہاں ہم ایم ایکس نیٹ کا سی پی یو ورژن انسٹال کر رہے ہیں ، کیوں نہیں جی پی یو ورژن انسٹال کریں؟ چونکہ میرا میک بک ایک AMD کارڈ ہے ، لہذا MXnet صرف CUDA کی حمایت کرتا ہے
1. ماخذ کوڈ ڈاؤن لوڈ کریں
ایک نئی ڈائرکٹری بنائیں اور اس ڈائرکٹری میں عمل کریں
git clone --recursive https://github.com/dmlc/mxnet2. مرتب کریں اور انسٹال کریں
انسٹال- mxnet-osx.sh اسکرپٹ کو سیٹ اپ یوکس ڈائریکٹری میں چلائیں۔ کچھ چیزوں کو درمیان میں مرتب کرنے کی ضرورت ہے۔ آپ کو تھوڑی دیر انتظار کرنا ہوگا ، اور پھر پاس ورڈ درج کرنا ہوگا ، اور خودکار تالیف اور تنصیب مکمل ہوجائے گی۔
توجہ فرمایے:
1. چونکہ آپ میک ڈائرکٹری میں فائلوں کو پڑھنا چاہتے ہیں ، لہذا آپ کو MXnet ماخذ کوڈ کی روٹ ڈائرکٹری میں انسٹالیشن اسکرپٹ کو چلانے کی ضرورت ہے۔
مثال کے طور پر ، mxnet کے سورس روٹ ڈائرکٹری میں پھانسی دیں
sh ./setup-utils/install-mxnet-osx.sh2. مستقبل میں اسکرپٹ چلانے کے لئے کچھ ازگر کے ماڈیولز کی ضرورت پڑسکتی ہے ، اسے پائپ انسٹال کرنے کی سفارش کی جاتی ہے
میک کے تحت تنصیب کا طریقہ کار بھی بہت آسان ہے: sudo easy_install pip
0x02 نمونہ رن
ہم کچھ نمونے چلانے کی کوشش کر سکتے ہیں جو ایم ایکس نیٹ کے ساتھ آتے ہیں ، یہاں ہم نیورل آرٹ کی مثال آزماتے ہیں
عصبی آرٹ ایک الگورتھم ہے جو کسی مشین کو کسی تصویر کو دوبارہ پینٹ کرنے کے لئے موجودہ پینٹنگ کے مصوری انداز کی نقل کرنے کی اجازت دیتا ہے۔
مثال کے طور پر ، ہم داخل کرتے ہیں

کے ساتھ

آخری نسل

1. پہلے مثال / عصبی طرز کی ڈائرکٹری کھولیں ، زیادہ تر مثالوں میں ریڈیمی موجود ہے ، آپ دوڑنے سے پہلے ایک نظر ڈال سکتے ہیں
اس نمونے کے README کا کہنا ہے کہ
پہلے ڈاؤن لوڈ ، اتارنا استعمال کریں۔ پہلے سے تربیت یافتہ ماڈل اور نمونہ آدانوں کو ڈاؤن لوڈ کریں
اس کے بعد مزید اختیارات دیکھنے کیلئے python nstyle.py کو استعمال کریں
پھر ہمیں اس ڈائرکٹری میں download.sh کو چلانا ہے
اسکرپٹ خود بخود ٹریننگ ماڈل vgg19.params کو ماڈل ڈائرکٹری میں ، اور ان پٹ مادی کو ان پٹ ڈائرکٹری میں ڈاؤن لوڈ کرے گا
2. ڈیمو چلائیں
چونکہ ہم CPU ورژن چلا رہے ہیں ، لہذا ہمیں اس طرح سے داخل ہونے کی ضرورت ہے
python nstyle.py --gpu -1 --max-num-epochs 150 - آؤٹ پٹ_ڈیر ~ / ڈیسک ٹاپ /--gpu: کون سا GPU استعمال کرنا ہے ، -1 کا مطلب CPU استعمال کرنا ہے
- میکس-نم-ایپوکس: تکرار کی زیادہ سے زیادہ تعداد ، یہاں ہم 150 مرتبہ دہراتے ہیں
--output_dir: نتائج آؤٹ پٹ
آپ اسے ایک بار بھی نہیں چل پائیں گے ، اور ایکس ایکس ایکس کے لئے نام نہی ماڈیول کا اشارہ ملے گا۔ عام طور پر ، اسی طرح کے ازگر ماڈیول انسٹال نہیں ہوتا ہے۔ آپ عام طور پر گوگل میں xxx کے نام والے کوئی ماڈیول کے تحت تنصیب کا طریقہ ڈھونڈ سکتے ہیں ، جن میں سے بیشتر پائپ کے ذریعے انسٹال کیا جاسکتا ہے۔
آپریشن کا نتیجہ
آئیے مختلف تکرار کے نتائج پر ایک نظر ڈالیں
10 بار:
50 بار:

100 بار:

150 بار:

یہ دیکھا جاسکتا ہے کہ زیادہ تکرار ، بہتر اثر۔ یقینا. چونکہ گہری سیکھنے اعصابی نیٹ ورک کی بہت سی پرتوں پر مشتمل ہے ، لہذا حساب کتاب کی مقدار بہت زیادہ ہے۔ یہاں تک کہ اگر CPU i7 ہے تو ، 150 تکرار میں درجنوں منٹ لگیں گے۔ مشروط طور پر دیکھیں عہدیدار GPU ورژن استعمال کرنے کی کوشش کر سکتے ہیں ، جو وقت کو چند منٹ تک مختصر کرسکتا ہے ، یا یہاں تک کہ کلاؤڈ پلیٹ فارم پر چل سکتا ہے۔
نمونے کا مخصوص اصول ضمیمہ کے دوسرے لنک کا حوالہ دے سکتا ہے۔
حوالہ ضمیمہ:
https://zhuanlan.zhihu.com/p/20634163