متعلقہ معلومات
کوشش کریں
گیم ٹیکسٹ میں کلیدی لفظ نکلوانے کی کوشش اور انکشاف
1. ٹیکسٹ کی ورڈ نکالنے کا ماضی اور حال
مضامین کی پیش کش میں مختلف سطحیں ہیں ، موٹے سے لے کر ٹھیک تک ، اسے اقسام (زمرے) ، واقعات (عنوانات) ، نمائندہ الفاظ (کلیدی الفاظ) وغیرہ میں تقسیم کیا جاسکتا ہے کلیدی الفاظ مضمون کی پیش کش کا ایک اہم حصہ ہیں۔ متن کے کلیدی الفاظ کو "مضمون" کے طور پر سمجھا جاسکتا ہے اور پورے مضمون کا بنیادی نچوڑ ، اور یہ ایک انتہائی عام مضمون کی فطری زبان کی نمائندگی ہے۔ زیادہ درست ٹیکسٹ کیورڈز بعد میں تجویز کردہ نظام میں زیادہ درست ٹیکسٹ مواد کی خصوصیات لاسکتے ہیں اور اسی نوعیت کے اعلی معیار کے مضامین کو یاد کر سکتے ہیں؛ ایک ہی وقت میں ، اعلی معیار کے مطلوبہ الفاظ کو بھی براہ راست مواد کے آپریشن اور صارف کی سفارش کے لئے درجہ بندی ٹیگ کے بطور استعمال کیا جاسکتا ہے۔ ، ترمیم اور کام کرنے والے ساتھیوں کی کام کی کارکردگی کو بہتر بنائیں۔
متن کی ورڈ نکالنے کے مسئلے نے بڑی تعداد میں محققین کی توجہ مبذول کرلی ہے۔ لفظ وزن کے سب سے آسان TF-IDF حساب سے لیکر ٹیکسرینک اور ایل ڈی اے جیسے غیر منظم طریقوں تک ، سیکو 2 سیکیک جیسے بڑے پیمانے پر استعمال ہونے والے عصبی نیٹ ورک کے ماڈلز تک ، مطلوبہ الفاظ کی کھینچنے کے شعبے میں بہت سارے طریقے اور ریسرچ موجود ہیں۔
2. کھیل کے متن میں مطلوبہ الفاظ کی نکالنے کا جائزہ
مختلف قسم کے گیم ٹیکسٹس جیسے گیم اسٹریٹیجیز ، نوووائس گائیڈز ، اور پروموشن گائیڈز کو کمپنی کے اندرونی ای اسپورٹس اور گیم سنٹرز اور دیگر جامع گیم پروڈکٹس میں جمع کرادیا گیا ہے۔ مطلوبہ الفاظ کے ٹیگز کے ساتھ گیم کے مناسب متن کو کیسے لیبل بنایا جائے؟ اور مشمولات کو صحیح صارفین تک پہنچانا ایک اہم مسئلہ بن گیا ہے۔
گیم ٹیکسٹ کی ورڈ کو نکالنے کی ہماری تلاش میں ، ہم نے گراف پر مبنی غیر معاشرتی طریقہ ٹیکسٹرنک اور زیر نگرانی Seq2Seq نیورل نیٹ ورک کا طریقہ آزمایا اور دونوں طریقوں کی کارکردگی کا ابتدائی موازنہ کیا۔
عصبی نیٹ ورکس پر مبنی نگرانی کے طریقوں میں عام طور پر بہتر پیرامیٹرز سیکھنے کے لled لیبل والے ڈیٹا کی ایک خاص مقدار کی ضرورت ہوتی ہے۔ اس منصوبے اور اعداد و شمار کی اصل صورتحال کے ساتھ مل کر عصبی نیٹ ورک کی تربیت کی ضروریات کو پورا کرنے کے ل we ، ہم نے موبائل کیو کیو پلیٹ فارم کے گیم سنٹر میں درجہ بندی اور لیبلنگ کے ساتھ گیم ٹیکسٹ کے تقریبا 3030،000 ٹکڑے جمع کیے تھے ، اسی طرح کی ٹیکسٹ کٹوتی کے بعد ، کم معیار کے متن کی فلٹرنگ پروسیسنگ کے بعد ، آخر کار 24،000 ڈیٹا کے نمونے حاصل کیے گئے۔ اس کارپس کی متن کی لمبائی چند سو سے لیکر ایک ہزار الفاظ سے زیادہ ہے اور ہر نمونے میں مصنوعی طور پر لیبل لگائے گئے کلیدی الفاظ has ~ 6 ہیں اور مجموعی طور پر تقریبا 90 ،000 ०، 90،000. ہیں۔ < متن ، مطلوبہ الفاظ > ہاں the کارپس میں مختلف مشمولات کے متن شامل ہیں جیسے نوسکھ promotion ہدایت نامہ ، پروموشن گائیڈ ، گیم کا تعارف وغیرہ ، اور اس میں مشہور کھیلوں کا احاطہ کیا گیا ہے جیسے بادشاہ کی شان ، ہر دن شاندار جنگ ، دیوتا جنگ ، اور ہر روز تیز دوڑنا۔ تجربے نے تصادفی طور پر 24،000 سے زیادہ نصوص کو 20000 کے ٹریننگ سیٹ ، 2000 کا توثیق سیٹ اور 2000 کے ٹیسٹ سیٹ میں تقسیم کیا؛ پہلے سے چلنے والے عمل میں ، جِیبا ٹول کو متن کو الگ کرنے کے لئے استعمال کیا جاتا تھا ، اور لفظ الفاظ کو الگ کرنے سے پہلے ہی گیم کی الفاظ کو درآمد کیا جاتا تھا۔ الفاظ کی تقسیم کی درستگی کو بہتر بنانے کے لئے لغت۔
تین ، دو طرح کے ٹیکسٹ کی ورڈ کو نکالنے کے ماڈل
1. ٹیکسٹ رینک پر مبنی گیم ٹیکسٹ کی ورڈز کو نکالنے کا ایک طریقہ
TextRank الگورتھم کا خیال پیج رینک کی ویب رینکنگ الگورتھم پر براہ راست کھینچتا ہے ، K لمبائی ونڈو میں الفاظ کے ملحقہ تعلقات کو PR الگورتھم میں لنک پوائنٹنگ ریلیشنشٹی کی نمائندگی کرنے کے لئے استعمال کرتا ہے ، جو بالکل پیجرنک کے تکراری فارمولے کی طرح ہے ، یعنی
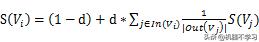
. ان کے درمیان،
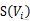
کیا میرا اہم وزن ہے ،
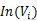
کیا الفاظ کا مجموعہ جو لفظ کی طرف اشارہ کرتا ہے ،
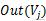
یہ الفاظ کا ایک مجموعہ ہے جو لفظ کی طرف اشارہ کرتا ہے۔ فارمولے کا حساب کتاب تکرار کے ذریعے کیا جاتا ہے ، اور آخر میں ہر لفظ کی اہمیت کو ترتیب سے ترتیب دیا جاتا ہے تاکہ لفظ کی اہمیت ہو۔
ٹیکسٹ رینک پر مبنی طریقہ آسان اور موثر ہے ، اور رفتار قابل قبول حد میں ہے۔ تاہم ، اس طریقہ کار میں دو واضح کوتاہیاں ہیں۔
1. مطلوبہ الفاظ کا منبع محدود ہے ، جو صرف اس دستاویز کی تمام الفاظ کی جمع ہے ، اور مزید مطلوبہ الفاظ کے تاثرات سیکھنا مشکل ہے۔
مضمون کے خلاصہ کلیدی لفظی اظہار کو "پیدا" کرنا بھی ناممکن ہے۔
2. اگرچہ ٹیکسٹرنک کسی مقررہ فاصلے والے ونڈو میں مطلوبہ الفاظ کی ہم آہنگی جیسی معلومات پر غور کرتی ہے ، لیکن پھر بھی اعلی تعدد والے الفاظ کو زیادہ وزن دینے کو ترجیح دیتی ہے ، لہذا اس کا موازنہ اصل استعمال میں TF-IDF جیسے طریقوں سے کیا جاتا ہے۔ زیادہ فائدہ نہیں ہے۔
ٹیکسٹرنک سوچنے میں آسان ہے اور اس پر عملدرآمد کرنا آسان ہے۔ یہاں ایسے ماڈیولز ہیں جن کو براہ راست مختلف این ایل پی ٹول کٹس میں کہا جاسکتا ہے ، جیسے ازگر میں مقیم جیبہ ، جاوا میں مقیم ہنالپ ، وغیرہ۔
2. Seq2Seq کا پس منظر
چونکہ سیکہ 2 سیکیک ماڈل تجویز کیا گیا تھا ، اس کو عصبی مشین ترجمہ ، شبیہہ اور متن کی تفصیل پیدا کرنے ، اور متن کا خلاصہ بنانے کے شعبوں میں وسیع پیمانے پر استعمال کیا گیا ہے۔ کلیدی الفاظ کو نکالنا بھی اسی خط میں ہے جس طرح متن کا خلاصہ کیا گیا ہے ، اور اسکالرز نے بھی عصبی نیٹ ورک کے مختلف ماڈلز کا استعمال کرتے ہوئے اس کام میں مختلف کوششیں کیں ہیں۔
سیکو 2 سیکیک ماڈل کو اکثر انکوڈر-ڈیکوڈر ماڈل کہا جاتا ہے ۔دوقابے انکوڈر اور ڈیکوڈر کے مساوی ہیں ۔انکوڈر اور ڈیکوڈر عام طور پر عام آر این این یونٹوں ، یا ایل ایس ٹی ایم یونٹوں پر مشتمل ہوتے ہیں اور GRU یونٹ۔ سی این این یا دیگر نیٹ ورک ڈھانچے پر مبنی Seq2Seq اس مضمون میں شامل نہیں ہے۔ ایک عام سیکو 2 سیکیک ماڈل ذیل میں شکل 1 میں دکھایا گیا ہے۔
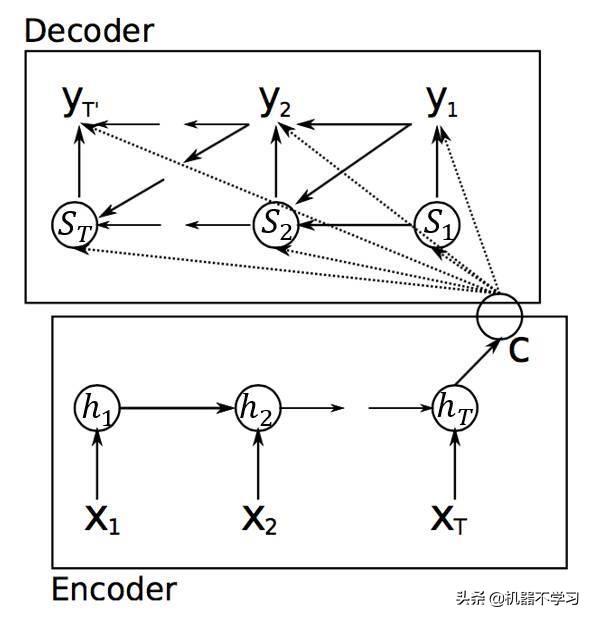
چترا 1 انکوڈر-ڈویکڈر ماڈل کا اسکیماتی آریھ
چترا 1 میں ، نچلا خانہ Seq2Seq ماڈل کا انکوڈر ہے ،
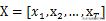
کیا منبع ترتیب کی ان پٹ ہے ، جو کلیدی لفظ نکالنے میں منبع متن سے مساوی ہے؛ اوپری باکس Seq2Seq ماڈل کا ڈیکوڈر ضابطہ کشندہ ہے ،
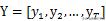
یہ ڈی کوڈر کی پیداوار ہے ، جو مطلوبہ الفاظ کی آؤٹ پٹ سے ملتی ہے۔ مثال کے طور پر کلیدی لفظ نکلوانا ، ہر بار کے آؤٹ پٹ ویکٹر y کو سافٹ ویکس سے منسلک کیا جائے گا تاکہ الفاظ کے ہر لفظ کے امکانات کا حساب لگ سکے (کارپس میں بڑی تعداد میں الفاظ کی وجہ سے ، عام طور پر ہر لفظ کا حساب کتاب ہوتا ہے) ضرورت سے زیادہ پیچیدگی کے مسئلے کے ل many ، بہت سارے اسکالرز نے اس مسئلے کو حل کرنے کے لئے بہتری کی تجویز پیش کی ہے ، جیسے https://arxiv.org/pdf/1412.2007.pdf)۔
جیسا کہ آپ مذکورہ اعداد و شمار میں انکوڈر باکس سے دیکھ سکتے ہیں ،
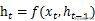
، پوشیدہ پرت ویکٹر کا حساب ہر وقت پر کیا جاتا ہے
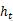
پچھلی پوشیدہ پرت کے لئے آؤٹ پٹ
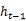
اور موجودہ ٹائم مرحلہ ان پٹ
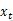
مشترکہ کارروائی کا نتیجہ۔ ڈوکوڈر حصے کے ذریعہ قبول کردہ ان پٹ ویکٹر سی (شکل 1) انکوڈر حصے کے آؤٹ پٹ ویکٹر سے آتا ہے ، جو عام طور پر انکوڈر کے آخری وقت کے پوشیدہ پرت کی پیداوار ہوتا ہے
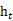
، کسی کام میں ، یہ کئی پوشیدہ پرت ویکٹروں یا فنکشن ٹرانسفارمیشن کا مجموعہ بھی ہوسکتا ہے ، جو ہے
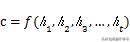
. ڈیکوڈر حصے کا پوشیدہ پرت اسٹیٹ ویکٹر حساب کتاب ہے
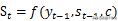
، یعنی ہر دفعہ کی پوشیدہ پرت
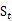
، ایک ہی لمبائی کے ایک جیسے c کا استعمال کرتے ہوئے حساب لگائے جاتے ہیں۔ آؤٹ پٹ ویکٹر کا کوٹواچک حصہ
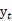
حساب کتاب انکوڈر سے بھی اسی معلومات پر انحصار کرتا ہے ، جیسا کہ شکل 1 میں دکھایا گیا ہے ، یہ معلومات اب بھی وہی سی ہے۔
مذکورہ بالا بحث سے یہ دیکھا جاسکتا ہے کہ ، عام طور پر ، ٹیکسٹ خلاصہ ، مشین ترجمہ وغیرہ میں ، ڈیکوڈر حصے کے ذریعہ قبول کردہ ماخذ کے متن سے ان پٹ معلومات صرف ایک طے شدہ لمبائی ویکٹر سی (چاہے ان پٹ متن بہت لمبا ہو) ، اور ایک ایک مقررہ طوالت والے ویکٹر کو ترجمہ یا مطلوبہ الفاظ کی سمری معلومات میں ڈی کوڈ کرنے سے عام طور پر کارکردگی کا ایک بڑا نقصان ہوتا ہے۔ 2014 میں بہادناؤ کی جانب سے پیش کردہ توجہ کا طریقہ کار اس مسئلے کو بہتر طور پر حل کرسکتا ہے ، اور اگلے دو یا تین سالوں میں ، یہ ترجمے ، خلاصہ ، کلیدی لفظ نکالنے ، شبیہہ متن تخلیق اور یہاں تک کہ جذباتی تجزیہ کے شعبوں میں وسیع پیمانے پر استعمال ہوتا رہا ہے۔
توجہ میکانزم پر مبنی Seq2Seq ماڈل انکوڈر انکوڈنگ حصے میں روایتی ماڈل سے مختلف نہیں ہے ، اور توجہ کا طریقہ کار بنیادی طور پر ڈویکڈر حصے پر مرکوز ہے ، جیسا کہ شکل 2 میں دکھایا گیا ہے۔ اعداد و شمار کا نچلا حصہ سیکو 2 سیکیک کا انکوڈر حصہ ہے۔ ظاہر ہے ، اعداد و شمار سے ، یہاں کے انکوڈر میں شکل 1 کے مقابلے میں ایک اور دوئدیہی آر این این حصہ ہے۔ اس کی وجہ نیٹ ورک کو دو سمتوں سے معلومات سیکھنے کے قابل بنانا ہے ، جو توجہ سے متعلق نہیں ہے۔
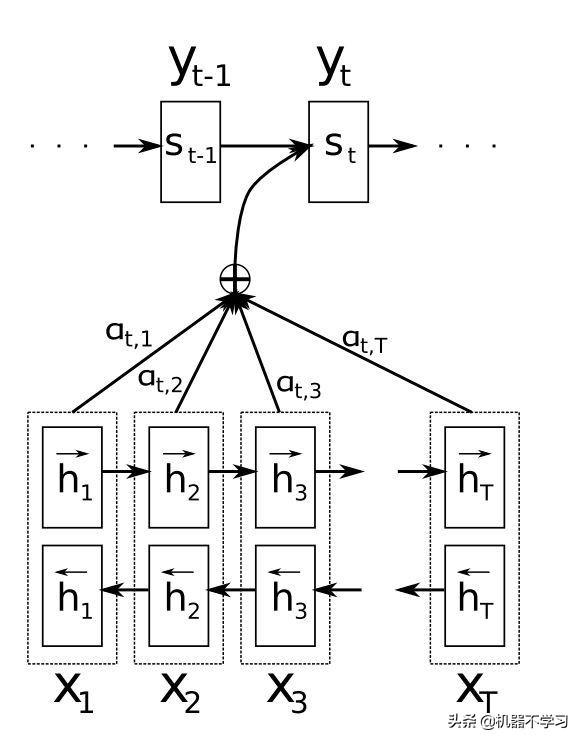
توجہ کے طریقہ کار کے ساتھ چترا 2 Seq2Seq ماڈل
عام سیکو 2 سیکیک ماڈل کی طرح ، شکل 2 میں ماڈل کو کوڈوڈر مرحلے میں بھی انکوڈر سے سی پڑھے گا ، لیکن اس سی کو آسانی سے انکوڈر کے آخری پوشیدہ پرت نوڈ کی قدر سے تبدیل نہیں کیا گیا اور اس کے بعد اس فعل کے ذریعہ تبدیل کیا گیا۔ انکوڈر کے ہر بار قدم کی پوشیدہ پرت نوڈ حالت پڑھیں اور وزن کی رقم حاصل کریں۔ جیسا کہ مندرجہ ذیل فارمولے میں دکھایا گیا ہے۔
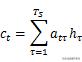
فارمولہ اور شکل 2 کا امتزاج کرتے ہوئے ، یہ واضح طور پر دیکھا جاسکتا ہے
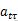
وقت پر کوڈوڈر کے مطابق ، انکوڈر انکوڈر سے

کسی بھی وقت ان پٹ کا وزن لکیری وزن اور خلاصہ کے ذریعہ حاصل کیا جاسکتا ہے
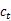
، یعنی ، ڈویکڈر کا وہ حصہ جو انکوڈر ویکٹر کو وقت پر قبول کرتا ہے۔ یہ شکل 2 سے دیکھا جاسکتا ہے کہ کوٹواچک حصے کی پوشیدہ پرت کا ریاستی ویکٹر
جیسا کہ حساب کیا جاتا ہے
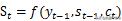
.
اور فارمولے میں
، تربیت کے بعد کارپورس سے حاصل کیا ، اور معمول کے فارمولے کے ذریعے ، کوٹواچ سے مختلف وقت
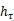
کے وزن
رقم کم کر کے 1 کردی گئی ہے۔
2. کاپی کرنے کے طریقہ کار پر مبنی سیکو 2 سیکیک-توجہ ماڈل
مندرجہ بالا توجہ پر مبنی ماڈل ایک سے زیادہ کاموں میں بڑے پیمانے پر استعمال ہوئے ہیں جیسے مشین ترجمہ ، ذہین سوال کا جواب ، اور متن کا خلاصہ۔ تاہم ، متن کا خلاصہ ، کلیدی لفظ نکلوانا ، اور ذہین سوال و جواب جیسے کاموں کے لئے ، ڈیکوڈر حصے کے ڈیزائن میں کچھ کوتاہیوں سے بچنا اب بھی مشکل ہے۔
بطور مثال کلیدی الفاظ نکالیں ، ڈویکڈر کا کوٹواس حصہ ہر دور میں ایک ذخیرہ الفاظ تیار کرے گا ، اس الفاظ کو نرم مکس کے ذریعہ شمار کیا جاتا ہے ، اور ذخیرہ الفاظ کا ماخذ سائز n کی ذخیرہ الفاظ ہے
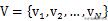
. حساب کتاب وقت کی قیمت کے تناظر میں ، یہ الفاظ عام طور پر ٹریننگ سیٹ میں تمام الفاظ پر مشتمل نہیں ہوتے ہیں۔ ٹریننگ سیٹ میں بڑی تعداد میں کم تعدد والی الفاظ صرف یو این کے ہی بدل سکتے ہیں the دوسری طرف ، ٹیسٹ سیٹ میں الفاظ مکمل طور پر ٹریننگ سیٹ میں ظاہر نہیں ہوسکتے ہیں۔ ، یقینا ، ممکنہ الفاظ V کی حد میں نہیں ہوسکتا ہے۔ اس سے متن کو خلاصہ کرنے اور مطلوبہ الفاظ کی نکلوانے میں اووئیو (لفظی الفاظ سے باہر) کہلاتا ہے۔ OOV کے اس رجحان کی وجہ سے ، جب نئے ٹیسٹ کارپس میں کچھ اہم الفاظ (OOV) الفاظ موجود ہیں ، چاہے وہ مطلوبہ الفاظ نکال رہا ہو یا خلاصہ پیدا کر رہا ہو ، ان اہم OOV الفاظ کی پیش گوئی صرف UNK کے طور پر کی جاسکتی ہے۔
او اوو کا مسئلہ Seq2Seq ماڈل میں لانے والی کوتاہیوں کے بارے میں بات کرنے کے بعد ، آئیے ذیل میں نقل کرنے والے طریقہ کار کے بارے میں بات کریں۔ اگر انسانوں سے دستاویز کو خلاصہ یا کلیدی الفاظ کو بہتر بنانے کے لئے کہا جاتا ہے تو ، وہ ماضی میں سیکھا ہوا اپنا پس منظر کا علم اور اس خلاصہ کو تحریر کرنے کے لئے استعمال نہیں کرے گا بلکہ اصل متن سے کچھ اہم متن کو "کاپی" یا "اقتباس" بھی بنائے گا۔ . ہم مشین کے خلاصہ (کلیدی لفظ نکالنے) کے کام کا موازنہ کرتے ہیں۔ روایتی ماڈل اکثر ٹریننگ کارپس میں سیکھے گئے پیرامیٹرز کا استعمال کرتے ہیں۔ جب تخلیق کرتے وقت پیش گوئی کرتے ہیں کہ الفاظ کے کس لفظ کو ایک خاص پوزیشن پر ایک ایک کرکے منتخب کرنا چاہئے؛ اگر اصلی متن میں متعدد الفاظ موجود ہوں تو اہم کلیدی الفاظ الفاظ میں نہیں ہیں ، لہذا بدقسمتی سے ، ان الفاظ کو مطلوبہ الفاظ کی فہرست میں تیار کرنے کا کوئی امکان نہیں ہے۔ جیتاو گو ایٹ اللہ نے انسانی "کاپی کرنا" اور "کاپی کرنا" کی شکل لی اور سیکیپ 2 سیکیک میں توجہ کا نمونہ لے کر کاپی کرنے کا طریقہ کار متعارف کرایا ، جس نے مطلوبہ الفاظ کے نکلوانے اور تجریدی کام پر OOV معاملات کے اثرات کو بہت حد تک بہتر بنایا۔ یہ نیٹ ورک ماڈل انکوڈر حصے میں بھی ایک روایتی شکل ہے ، اور تبدیل نہیں ہوا ہے but لیکن ڈیکوڈر حصے میں ، کاپی کرنے والے طریقہ کار کے بارے میں بہت سارے حساب کتاب شامل کردیئے گئے ہیں ، جیسا کہ شکل 3 میں دکھایا گیا ہے۔
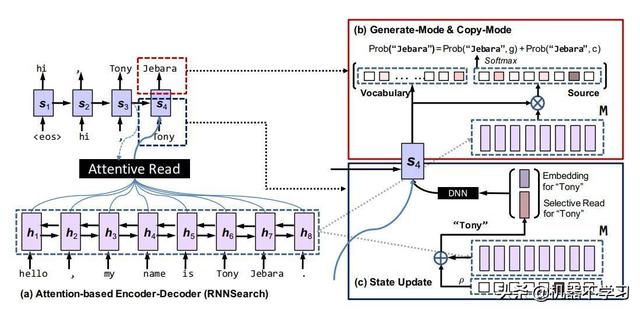
چترا 3 Seq2Seq ماڈل کاپی کرنے کے طریقہ کار کے ساتھ
جیسا کہ شکل 3 سے دیکھا جاسکتا ہے ، ماڈل کا ڈوکوڈر حصہ پوشیدہ پرت اسٹیٹ ویکٹر میں ہے
تازہ ترین معلومات اور
پیش گوئیاں گذشتہ ماڈلز سے خاصی مختلف ہیں۔ جیسا کہ شکل 3 کے نیچے دائیں میں دکھایا گیا ہے ، اسٹیٹ اپ ڈیٹ کے عمل کو واضح طور پر کئی حصوں میں تقسیم کیا جاسکتا ہے: پہلا حصہ بائیں طرف کا ٹھوس نیلے رنگ کا تیر ہے۔یہ توجہ سے پڑھنے والی معلومات ہے ، جسے ہم عام طور پر توجہ کہتے ہیں۔ معلومات
The دوسرا حصہ ہے
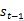
حصہ بھی سابقہ توجہ کے ماڈل جیسا ہی ہے؛ لیکن تیسرا حصہ
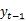
کی معلومات نہ صرف پچھلے ٹائم مرحلے کے نتائج کو سرایت کرنے کے لئے استعمال کی جاتی ہے بلکہ منتخب پڑھنے والے ویکٹر کے ساتھ بھی ٹکرا دی جاتی ہے ۔یہ ویکٹر درحقیقت توجہ کے طریقہ کار سے ملتے جلتے طریقہ سے حساب کیا جاتا ہے۔ کوٹواچک اور انکوڈر کی پوزیشن کا حساب لگایا جاتا ہے پوشیدہ پرت کی حالت سے متعلق ہر مرحلے میں پوزیشن سے متعلق معلومات اگلے کاپی موڈ کے لئے معلومات فراہم کرتی ہے۔
چترا 3 کے اوپری دائیں حصے میں جنریٹ موڈ اور کاپی موڈ مطلوبہ الفاظ کے متن کو تیار کرنے کے لئے دو ممکنہ حساب کتابی فارمولے ہیں۔ بائیں طرف جنریٹ موڈ کلاسیکی ماڈل کی طرح ہی پیدا ہوتا ہے while جبکہ کاپی موڈ ماخذ کی ترتیب سے پیدا ہونے والے ہر لفظ کے امکانات کا حساب لگاتا ہے ، اور حاصل کرنے کے لئے دونوں امکانی امور کو ایک ساتھ جوڑ دیا جاتا ہے
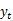
ہدف کے لفظ کے محل وقوع کا امکان ، جیسا کہ فارمولے میں دکھایا گیا ہے۔
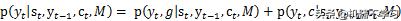
نوٹ کریں کہ فارمولے میں جی اور سی بالترتیب دو نسل کے طریقوں کی نمائندگی کرتے ہیں۔ جی اور سی کا حساب کتاب اور تیار کردہ الفاظ
اس کا تعلق دو الفاظ V اور X (ماخذ ٹیکسٹ الفاظ) کے مابین تعلقات سے ہے۔ اصل متن میں چترا 2 کی ایک واضح وضاحت ہے ، لہذا میں اسے یہاں دوبارہ نہیں دوں گا۔
چوتھا ، گیم ٹیکسٹ کے کلیدی لفظ نکالنے میں کاپی کرنے والے میکانزم ماڈل کی اہمیت
جیسا کہ مذکورہ بالا تفصیل سے دیکھا جاسکتا ہے ، اگر کسی متن میں اہم مطلوبہ الفاظ پوری ٹریننگ سیٹ میں اعلی تعدد والے الفاظ نہیں ہیں اور الفاظ میں نہیں ہیں ، تو روایتی توجہ-سیکہ 2 سیکیک لاچار کی صورت میں ، نقل کرنے کا طریقہ کار براہ راست اصل متن سے ہوسکتا ہے۔ کاپی "اس مسئلے کو بہتر طریقے سے حل کرسکتی ہے۔ ایک ہی وقت میں ، ایک کلاسیکی جنریٹ ماڈل کے طور پر ، ٹیکسٹرنک اور دیگر طریقوں کے مقابلے میں ، یہ ہزاروں ٹریننگ کارپورا سے سیکھے گئے بہت سارے علم میں اضافہ کرتا ہے ، جو "نکالنے" اور "نسل" کے ماڈلز کے فوائد کو اچھی طرح توازن بخش سکتا ہے۔ .
آئیے اس مضمون کو ایک آسان مثال کے ساتھ ختم کریں۔
نمونہ: "کنگز کا اتحاد" 5V5 کنگز وادی تین طرفہ ٹاور شوق کا کھیل < eos > "لیگ آف کنگز" میں 5v5 لڑائیاں بہت سے کھلاڑی پسند کرتے ہیں۔ کھلاڑی اپنے آپ میچ کرسکتے ہیں یا دوستوں کو ایک ساتھ مل کر ہیکنگ کھیلنے کے لئے مدعو کرسکتے ہیں۔ 5v5 کی لڑائی میں ، یہ کوئی ذاتی شو آپریشن نہیں ہے جو سامعین کو کنٹرول کرسکتا ہے ، اور ٹیموں کے درمیان باہمی تعاون کی ضرورت ہے۔ معقول لائن اپ ٹککاؤ ، میدان جنگ میں مزدوری کی واضح تقسیم ، ہیروز کے ل players کھلاڑیوں کی آپریشن کی مہارت ... (اقتباس)
گراؤنڈ ٹرuthت: کنگز کا 5v5 وادی Kings کنگز کا اتحاد Nov نوائس
کاپی میکانزم کے ساتھ Seq2Seq (ٹاپ 5)
ٹیکسٹرنک (ٹاپ 5)
1. کنگز کالج
ہیرو
کنگز کی لیگ
2. دشمن
3. 5v5 کنگز وادی
3. مار ڈالو
4. نووایس
4. ٹیم کے ساتھی
5. کنگز کے 5v5 اتحاد
5. ترقی
2. دشمن
3. مار ڈالو
4. ٹیم کے ساتھی
5. ترقی
ٹیسٹ سیٹ پر جانچ کے بعد ، یہ دیکھا جاسکتا ہے کہ ڈی این این پر مبنی سیکیک 2 سیکیک طریقہ ٹیکسٹرنک کے پی 1 @ 5 سے 4٪ زیادہ ہے ، آر 1 @ 58٪ زیادہ ہے ، اور ایف 15 55.4٪ زیادہ ہے ، جو ابتدائی طور پر اس طریقہ کار کی تاثیر کو ثابت کرتا ہے۔
اگلا ، ہمیں اب بھی اعداد و شمار اور ماڈل کی دو سطحوں سے کلیدی الفاظ نکالنے کی کارکردگی کو مزید بہتر بنانے کی ضرورت ہے ، اور ہم ملٹی ماڈل کے نتائج کو جوڑنے کے تناظر سے نتائج کی مضبوطی کو بڑھانے پر بھی غور کرسکتے ہیں۔
اصل متن WeChat آفیشل اکاؤنٹ-ٹینسنٹ Wenquxing (tencent_wisdom) پر شائع ہوا تھا